基于单张
基于单张rgb图像实现不同人体重建模型的融合方法
技术领域
1.本发明涉及计算机视觉处理领域,尤其涉及一种基于单张
rgb
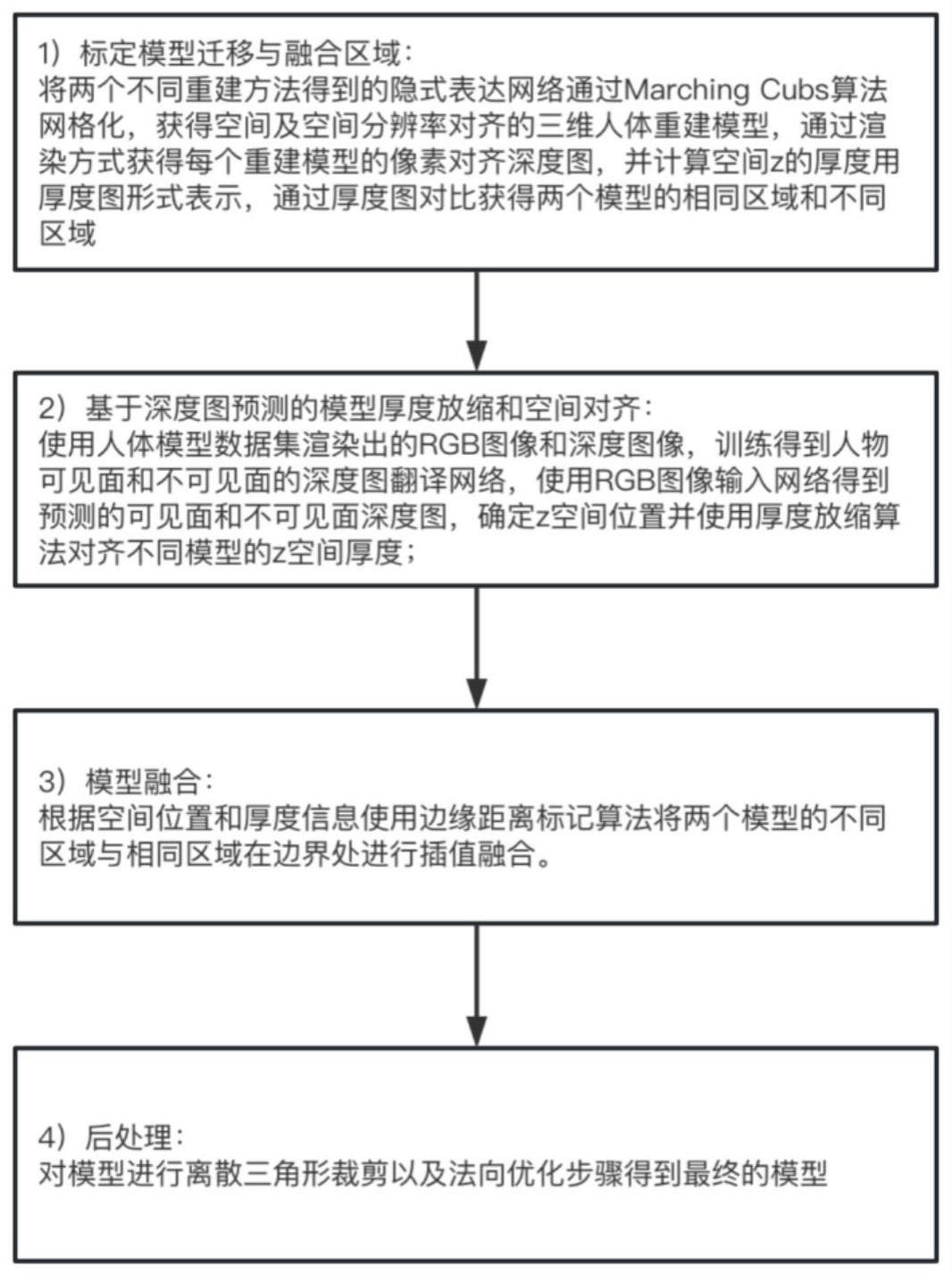
图像实现不同人体重建模型的融合方法
。
背景技术:
2.人体三维重建是三维重建领域中的的重要细分领域
。
低成本
、
便捷的获取人体三维模型有广泛的应用空间和应用价值
。
传统的方法耗时长
、
设备昂贵
、
获取难度高
、
难以应用到日常场景中
。
当前,深度学习可以利用神经网络强大的拟合能力从图像中学出合理映射,但也存在着显著的缺点;由于学习信息的限制,不同的单张图重建方法难以兼顾多方面的重建优势,一方面蒙皮多人线性模型
(smpl
:
skinned multi-person linear model)
系列方法可以发挥重建的姿态和人体结构优势,但难以兼顾优良完整的衣物重建;另一方面隐式表达系列方法具有重建精度高和表达复杂高维三维结构能力强的优势,但难以兼顾合理的人体结构
。
在单张图人体三维重建中,发挥模型自由表达能力与利用参数化先验做姿态规范是一个天平的两端,重建方法侧重于某一端时,另一端的重建优势就会受到限制
。
技术实现要素:
3.本发明的目的是为了提供基于单张
rgb
图像实现不同人体重建模型的融合方法,提高重建精度
。
4.为解决以上技术问题,本发明的技术方案为:基于单张
rgb
图像实现不同人体重建模型的融合方法,包括:
5.步骤
s100
:标定模型迁移与融合区域:将两个不同重建方法得到的隐式表达网络通过
marching cubs
算法网格化,获得空间及空间分辨率对齐的三维人体重建模型;基于单张
rgb
图输入两个三维人体隐式重建模型;通过渲染方式获得每个模型像素对齐的空间深度图,并计算对应的空间厚度图,通过厚度图对比获得两个模型的相同区域和不同区域;
6.步骤
s200
:基于预测深度图的模型厚度放缩和空间对齐:基于人体模型数据集渲染出的单张
rgb
图片和对应的空间深度图,训练得到人物可见面和不可见面的深度图网络,使用
rgb
图像输入网络得到预测的可见面深度图和不可见面深度图;确定z空间位置并使用厚度放缩算法对齐不同重建模型的z空间厚度;
7.步骤
s300
:模型融合:将两个重建模型的相同区域和不同区域在边界处进行插值融合;
8.步骤
s400
:后处理:将模型进行离散三角形裁剪以及法向优化
。
9.进一步地,步骤
s100
包括:
10.步骤
s110
:使用同一张人物
rgb
图片进行裁剪和去除背景后,用于两种三维人体隐式重建模型的输入,得到两个模型重建出的空间对齐的
marching cubes
立方体空间;两种三维人体隐式重建模型包括第一模型和第二模型;
11.步骤
s120
:遍历已获得的两个
marching cubes
立方体空间,获取每个点的数值,统
计
x-y
二维空间上每个
cubes[z][x][y]
>v的点到相机视角的距离得到第一空间深度图和第二空间深度图;其中,v值表示采样点经过计算后是否在重建模型表面的概率值;
[0012]
步骤
s130
:基于第一空间深度图和第二空间深度图计算对应的第一空间厚度图和第二空间厚度图;
[0013]
步骤
s140
:基于第一空间厚度图和第二空间厚度图进行逐像素对比,得到两个重建模型在
marching cubes
立方体的
x-y
二维空间上的重合点和未重合点,得到两个立方体空间中的差异和重合信息,判定第一模型的保留区域和第二模型迁移区域;
[0014]
步骤
s150
:基于边缘距离标记算法标记第一模型的保留区域和第二模型的迁移区域的边缘点
。
[0015]
进一步地,步骤
s110
中,第一模型为
icon
重建方法获得的三维人体隐式重建模型;第二模型为基于
pifu
重建方法获得的三维人体隐式重建模型
。
[0016]
进一步地,步骤
s120
中,v值采用
0.5
;
0.5
作为重建表面,大于
0.5
视为在重建表面外,小于
0.5
视为在重建人体表面的内部
。
[0017]
进一步地,其中,步骤
s150
包括:
[0018]
步骤
s151
:遍历所有共同点,标记与共同点相邻的不同点,标记为距离1,之后遍历距离1点,再标记所有未被标记且与之相邻的不同点,标记为距离2,以此类推,通过反复标记将所有可达的不同点标记为与最近相同点的距离;
[0019]
步骤
s152
:设定一个阈值
x
,将距离大于阈值
x
的点均标记为迁移部分的点集,对于不同部分的迁移点集的相邻点,反复标记直到距离1被加入迁移点集;这时所有的标记点均为需要迁移拼接的点集;在得到迁移拼接点集合之后,对模型表面距离为1的点向第一模型保留点集合中继续拓展n个像素,通过判断距离为1的点的相邻点是否为相同点,若是则加入新的集合,作为相同区域的插值融合部分;
[0020]
步骤
s153
:通过步骤
s151
和步骤
s152
反复递归,得到第一模型保留区域和第二模型迁移区域分别距离两部分边缘n个像素的插值区域
。
[0021]
进一步地,步骤
s200
包括:
[0022]
步骤
s210
:使用人体模型数据集渲染出的单张
rgb
图片,与对应的深度图作为训练对,通过神经网络
resnet
构成的图像生成网络分别训练与
rgb
图像对应的可见面深度图网络与不可见面深度图网络,得到
rgb
图与图像角度增加
180
度的深度图网络其中,
gd表示训练完成的深度图网络,表示生成可见面深度图的网络,表示生成不可见面深度图的网络;基于训练的可见面深度图网络与不可见面深度图网络得到预测的可见面深度图和不可见面深度图;
[0023]
步骤
s220
:基于预测的可见面深度图和不可见面深度图计算逐像素差值得到预测空间厚度图,将预测空间厚度图与第一模型和第二模型空间厚度图中对应像素厚度值做对比,确定z空间厚度和z空间位置;
[0024]
步骤
s230
:使用厚度放缩算法放缩迁移部分的厚度,使第一模型和第二模型在z空间上相匹配
。
[0025]
进一步地,步骤
s210
中,训练可见面深度图网络与不可见面深度图网络时,特征匹配损失为:
[0026][0027]
其中,g表示深度图网络中的生成器,dk
表示深度图网络中的第k个判别器,
rgb
表示的是输入图片,
deep
表示的是对应的深度图,e(rgb
,
deep)
表示与
rgb
和
deep
相关的计算函数,
t
表示神经网络总层数,
ni表示神经网络每层的元素数量,表示的是输入真实深度图的判别器参数和输入生成深度图的判别器参数之间的
:1
损失
。
[0028]
进一步地,步骤
s230
中,计算第一模型的空间平均厚度
ta,计算深度预测图与第一模型对应区域的平均厚度
t
ad
,第一模型缺失部分的预测厚度
t
al
,通过比例计算获得第二模型迁移至第一模型部分的厚度
t
b2a
,将第二模型对应部分的厚度转化为
t
b2a
。
[0029]
进一步地,步骤
s300
包括:将第二模型保留部分和第二模型迁移部分进行插值计算,插值公式为:
[0030]r=
x0*(1-p)+x1*p
[0031]
其中,r为插值结果,
x0、x1代表空间插值点,0<
p
<1是插值像素的偏移量,远离融合区域i个像素的偏移量为
i/n
,n代表融合范围的阈值
。
[0032]
进一步地,步骤
s400
包括:
[0033]
步骤
s410
:去除离散三角形,通过标记主体模型,删除所有与主体网格不相连的顶点与边构成的三角形片元,得到连续的重建网格;
[0034]
步骤
s420
:对模型进行重网格化,调整网格顶点位置,改变网格三角形在空间中面积大小存在较大差别的情况,使得空间中的网格三角形面积相等;
[0035]
步骤
s430
:使用训练集中的三维模型渲染出的单张
rgb
图片,与对应的法向图作为训练对,通过
resnet
构成的图像生成网络分别训练与
rgb
图像对应的可见面法向图与不可见面法向图网络,得到
rgb
图与图像角度增加
180
度的法向图网络gn
表示训练完成的法向图网络;
[0036]
步骤
s440
:将重网格后的顶点输入到一个顶点微调神经训练网络中,输出微调后的顶点,不改变网格的拓扑结构,将网格进行微渲染,得到可见面与不可见面的穿衣人体法向图,将步骤
s430
预测的特征法向与渲染得到的法向计算
l1
损失,作为迭代优化的损失函数
。
[0037]
本发明具有如下有益效果:
[0038]
一
、
本发明充分利用了深度学习的预测信息用于改进单张图像重建中人体姿态和宽松衣物不可兼得的问题
。
[0039]
二
、
本发明利用预测得到的可见面与不可见面深度图,得到模型空间位置并计算出厚度图,使用厚度图通过厚度放缩算法得到迁移部分的模型厚度,找到融合的空间位置与区域范围;借助人体预测深度图,使用边缘距离标记算法确定不同模型用于保留的相同区域和用于迁移融合的差异区域;
[0040]
三
、
本发明对模型边缘插值融合,改善融合过程中两个模型边缘匹配度的方式,对具有重建优势的第一模型中的缺失部分利用第二模型中的相应重建出的部分进行重建部分迁移融合在保证原模型细节优化的效果上,对不足之处做出改善,使融合后的模型更加自然流畅
。
通过以上工作,有效改善了单张
rgb
图像进行人体重建时的重建效果和衡量精
度
。
附图说明
[0041]
图1为本发明实施例的基于单张
rgb
图像实现不同人体重建模型的融合方法流程图;
[0042]
图2为发明实施例的基于单张
rgb
图像实现不同人体重建模型的融合流程图;
[0043]
图3为本发明实施例的基于单张
rgb
图像实现不同人体重建模型的融合结果展示图
。
具体实施方式
[0044]
为了使本发明的目的
、
技术方案及优点更加清楚明白,下面结合附图和具体实施例对本发明作进一步详细说明
。
[0045]
请参考图1,本发明为一种基于单张
rgb
图像实现不同人体重建模型的融合方法,其包括:
[0046]
步骤
s100
:标定模型迁移与融合区域:将两个不同重建方法得到的隐式表达网络通过
marching cubs
算法网格化,获得空间及空间分辨率对齐的三维人体重建模型;基于单张
rgb
图输入两个三维人体隐式重建模型;通过渲染方式获得每个模型像素对齐的空间深度图,并计算对应的空间厚度图,通过厚度图对比获得两个模型的相同区域和不同区域;
[0047]
步骤
s200
:基于预测深度图的模型厚度放缩和空间对齐:基于人体模型数据集渲染出的单张
rgb
图片和对应的空间深度图,训练得到人物可见面和不可见面的深度图网络,使用
rgb
图像输入网络得到预测的可见面深度图和不可见面深度图;确定z空间位置并使用厚度放缩算法对齐不同重建模型的z空间厚度;
[0048]
步骤
s300
:模型融合:将两个重建模型的相同区域和不同区域在边界处进行插值融合;
[0049]
步骤
s400
:后处理:将模型进行离散三角形裁剪以及法向优化
。
[0050]
本实施例中,将
icon(implicit clothed humans obtained from normals
重建方法和
pifu(pixel-aligned implicit function)
重建方法这两个不同重建方法得到的隐式表达网络通过
marching cubs
算法网格化,获得空间及空间分辨率对齐的两个三维人体重建模型;其中,基于
icon
重建方法获得的人体重建模型作为第一模型,基于
pifu
重建方法获得的人体重建模型作为第二模型;
[0051]
icon
重建方法的优势是使用
smpl
作为人体模型隐式表示的先验信息能很好表示人体模型复杂姿态,同时借助法向图使重建模型能表现更多局部细节,该方法局限处在于过强的先验使其难以完整表达宽松衣物的拓扑结构,重建后的模型在远离体表处存在衣物缺失情况;使用
pifu
重建方法作为权利要求中的b模型,该方法使用隐式方法表示人体表面,未使用任何先验信息,优势在于能够完整表达人体模型中远离体表的宽松衣物,局限性在于不能很好表现复杂人体姿态和局部细节
。
根据权利要求所包含的内容举例说明
。
为了克服
icon
和
pifu
重建两种单张图重建技术各自的局限性,结合两种重建模型的优势,通过本发明基于单张
rgb
图像实现不同人体重建模型的融合方法,使得最后的穿衣人体重建模型达到细节表现和整体衣物完善的效果
[0052]
图像输入:本发明要求两种模型的输入图像分辨率相同,使用同一张图像作为输入,在输入前要对人像
rgb
图做背景裁切
。
通过网络输入得到
icon
重建方法的衣物确实输出模型和
pifu
重建方法的细节不足输出模型后,保留
icon
重建方法输出模型作为第一模型,
pifu
重建方法输出模型作为第二模型,将
pifu
模型的衣物部分迁移至
icon
模型缺失部分
。
[0053]
下面针对图1的各个步骤进行具体说明
。
[0054]
步骤
s100
:标定模型迁移与融合区域阶段:
[0055]
将
icon
重建方法和
pifu
重建方法得到的隐式表达网络通过
marching cubs
算法网格化,获得空间及空间分辨率对齐的三维人体重建模型,通过渲染方式获得每个重建模型的像素对齐深度图,并计算空间z的厚度用厚度图形式表示,通过厚度图对比获得
icon
重建方法输出模型和
pifu
重建方法输出模型的相同区域和不同区域;具体包括如下步骤:
[0056]
步骤
s110
:使用同一张人物
rgb
图片进行裁剪和去除背景后,用于两种
icon
重建方法和
pifu
重建方法三维人体隐式重建模型的输入,得到两个模型重建出的空间对齐的
marching cubes
立方体空间;现有重建方法通常为
256
×
256
×
256
或
512
×
512
×
512。
[0057]
步骤
s120
:遍历已获得的
icon
重建方法和
pifu
重建方法的两个
marching cubes
立方体空间,获取每个点的数值,统计
x-y
二维空间上每个
cubes[z][x][y]
>v的点到相机视角的距离得到第一空间深度图和第二空间深度图;其中v=
0.5
用于生成人体的
marching cubes
网格模型,v值大小由两个重建模型的实际情况确定,用于过滤重建空间中偏离人体模型的离散噪声碎片
。
本步骤中v值表示的是采样点经过神经网络计算后是否在重建模型表面的概率值,通常以
0.5
作为重建表面,大于
0.5
视为在重建表面外,小于
0.5
视为在重建人体表面的内部
。
[0058]
步骤
s130
:利用
icon
重建方法和
pifu
重建方法的
marching cubes
空间深度即基于第一空间深度图和第二空间深度图计算对应的第一空间厚度图和第二空间厚度图,以厚度图形式表示;
[0059]
步骤
s140
:基于第一空间厚度图和第二空间厚度图进行逐像素对比,得到两个重建模型在
marching cubes
立方体的
x-y
二维空间上的重合点和未重合点,得到两个立方体空间中的差异和重合信息,判定第一模型的保留区域和第二模型迁移区域;
[0060]
步骤
s150
:基于边缘距离标记算法标记第一模型的保留区域和第二模型的迁移区域的边缘点用于步骤
s300
中的边缘融合,具体包括如下步骤:
[0061]
步骤
s151
:遍历所有共同点,标记与共同点相邻的不同点,标记为距离1,之后遍历距离1点,再标记所有未被标记且与之相邻的不同点,标记为距离2,以此类推,通过反复标记将所有可达的不同点标记为与最近相同点的距离
。
[0062]
步骤
s152
:设定一个阈值
x
,将距离大于阈值
x
的点均标记为迁移部分的点集,对于不同部分的迁移点集的相邻点,反复标记直到距离1被加入迁移点集
。
这时所有的标记点均为需要迁移拼接的衣物点集
。
在得到迁移拼接点集合之后,可以对模型表面距离为1的点向
icon
重建方法输出模型保留点集合中继续拓展n个像素,通过判断距离为1的点的相邻点是否为相同点,若是则可以加入新的集合,作为相同区域的插值融合部分
。
[0063]
步骤
s153
:通过步骤
s151
和步骤
s152
反复递归可以得到:
icon
重建方法人体模型人体主体保留区域和
pifu
重建方法人体模型衣物迁移区域分别距离两部分边缘n个像素的插值区域
。
[0064]
步骤
s200
,基于深度图预测的模型厚度放缩和空间对齐,包括:
[0065]
步骤
s210
:使用训练集中的三维模型渲染出的单张
rgb
图片,与对应的深度图作为训练对,通过
resnet
构成的图像生成网络分别训练与
rgb
图像对应的可见面深度图与不可见面深度图网络,得到
rgb
图与图像角度增加
180
度的深度图网络其中,训练可见面深度图网络与不可见面深度图网络时,特征匹配损失为:
[0066][0067]
其中,g表示深度图网络中的生成器,dk
表示深度图网络中的第k个判别器,
rgb
表示的是输入图片,
deep
表示的是对应的深度图,e(rgb
,
deep)
表示与
rgb
和
peep
相关的计算函数,
t
表示神经网络总层数,
ni表示神经网络每层的元素数量,表示的是输入真实深度图的判别器参数和输入生成深度图的判别器参数之间的
l1
损失
。
[0068]
步骤
s220
:得到两张深度图后,将其进行像素对齐
。
根据可见面深度图和可见面视角下增加
180
度的不可见面深度图计算逐像素差值得到厚度图
。
与
icon
重建方法输出模型和
pifu
重建方法输出模型的对应像素厚度值做对比,确定z空间厚度和z空间位置
。
[0069]
步骤
s230
:使用厚度放缩算法放缩迁移部分的厚度,使
icon
重建方法输出模型和
pifu
重建方法输出模型在z空间上相匹配
。
计算
icon
重建方法输出模型的空间平均厚度
ta,计算深度预测图与
icon
重建方法输出模型对应区域的平均厚度
t
ad
,
icon
重建方法输出模型缺失部分的预测厚度
t
al
,通过比例计算获得
pifu
重建方法输出模型迁移至
icon
模型部分的厚度
t
b2a
,将
pifu
模型该部分的厚度转化为
t
b2a
。
[0070]
步骤
s300
中,模型融合:根据空间位置和厚度信息使用边缘距离标记算法将两个模型的不同区域与相同区域在边界处进行插值融合;具体包括如下步骤:
[0071]
将第二模型保留部分和第二模型迁移部分进行插值计算,插值公式为:
[0072]r=
x0*(1-p)+x1*p
[0073]
其中,r为插值结果,
x0、x1代表空间插值点,0<
p
<1是插值像素的偏移量,远离融合区域i个像素的偏移量为
i/n
,n代表融合范围的阈值
。
[0074]
步骤
s400
,对模型进行离散三角形裁剪以及法向优化步骤得到最终的模型,包括:
[0075]
步骤
s410
:去除离散三角形,通过标记主体模型,删除所有与主体网格不相连的顶点与边构成的三角形片元,得到连续的重建网格;
[0076]
步骤
s420
:对模型进行重对模型进行离散三角形裁剪以及法向优化步骤得到最终的模型网格化,调整网格顶点位置,改变网格三角形在空间中面积大小存在较大差别的情况,使得空间中的网格三角形面积相等;
[0077]
步骤
s430
:使用训练集中的三维模型渲染出的单张
rgb
图片,与对应的法向图作为训练对,通过
resnet
构成的图像生成网络分别训练与
rgb
图像对应的可见面法向图与不可见面法向图网络,得到
rgb
图与图像角度增加
180
度的法向图网络gn
表示训练完成的法向图网络;
[0078]
步骤
s440
:将重网格后的顶点输入到一个顶点微调神经训练网络中,输出微调后的顶点,不改变网格的拓扑结构,将网格进行微渲染,得到可见面与不可见面的穿衣人体法
向图,将步骤
s430
预测的特征法向与渲染得到的法向计算
l1
损失,作为迭代优化的损失函数,提升重建质量
。
最后输出重建模型,从而实现三维人体重建
。
图3为本实施例中的融合效果展示
。
[0079]
本发明未涉及部分均与现有技术相同或采用现有技术加以实现
。
[0080]
以上内容是结合具体的实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明
。
对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单推演或替换,都应当视为属于本发明的保护范围
。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1