面向配电网边缘计算装置的
面向配电网边缘计算装置的d-pmu数据实时压缩方法
技术领域
1.本发明涉及一种配电网同步相量测量单元
(distribution-level phasor measurement unit
,
d-pmu)
数据实时压缩方法
。
特别是涉及一种面向配电网边缘计算装置的
d-pmu
数据实时压缩方法
。
背景技术:
2.各种先进的信息化与数字化技术在配电网中的应用加速了配电网的数字化转型
。
海量数据与广泛链接是数字配电网的基本特征
。
数字配电网利用边缘计算技术,实现量测数据的就地采集
、
分析
、
处理;边缘计算装置提取的有价值信息可进一步上传至云端,完成更加复杂的分析决策,形成了云边协同的电网运行架构
。
其中,以
d-pmu
为代表的先进的感知与量测技术,提升了网络的可观水平,是云边协同架构的基础
。
3.d-pmu
基于全球定位系统实现了数据同步,可以采集电压相量
、
电流相量
、
频率数据等,具有高达每秒
240
帧的上送速率
。
大量的
d-pmu
和高上送速率产生了海量数据,例如,以每秒
30
帧上送速率的
1100
个同步相量测量单元每天将产生
700gb
以上的数据,上送速率和
d-pmu
数量的增加都会造成数据量的线性增长
。
为了防止
d-pmu
数据传输对通信系统造成无法接受的延迟和阻塞,有必要在配电网边缘侧对
d-pmu
数据进行压缩
。
4.d-pmu
数据已经广泛应用于实时状态估计
、
拓扑识别
、
故障定位
、
电压无功控制等领域
。
相比于配电网数据采集与监视控制系统和智能量测体系,
d-pmu
的主要优势在于其精准时标同步和高上送速率
。
对于实时状态估计和故障定位而言,通常要求每秒
50
帧以上上送速率的
d-pmu
数据以保证应用的实时性
。
因此,
d-pmu
数据实时压缩算法应该在有效降低数据量的同时,避免引入较大的时延
。
5.数据压缩技术包括有损压缩和无损压缩两大类
。
无损压缩通常利用数据统计和有效的逐位编码技术,在数据重构时可以完全恢复所有原始信息
。
常用的无损压缩技术包括
huffman
编码
、lempel-ziv
编码
、
哥伦布编码等
。
无损压缩适用于数据精度要求较高的场合,压缩比通常较低
。
有损压缩强调以可控的误差去换取更好的压缩比
。
常用的有损压缩算法包括主成分分析
、
奇异值分解
、
小波变换等
。
但现有的有损数据压缩方法在压缩
d-pmu
数据时,大多需要一段时间内的数据作为输入,不能做到
d-pmu
数据的实时压缩,且算法运算量较大,在数字配电网边缘计算环境下的适用能力也有待探索
。
技术实现要素:
6.本发明所要解决的技术问题是,为克服现有技术的不足,提供一种考虑
d-pmu
数据变化特征,旨在实现边缘侧各类型
d-pmu
数据的高效压缩,缓解海量数据实时上送对通信系统造成压力的面向配电网边缘计算装置的
d-pmu
数据实时压缩方法
。
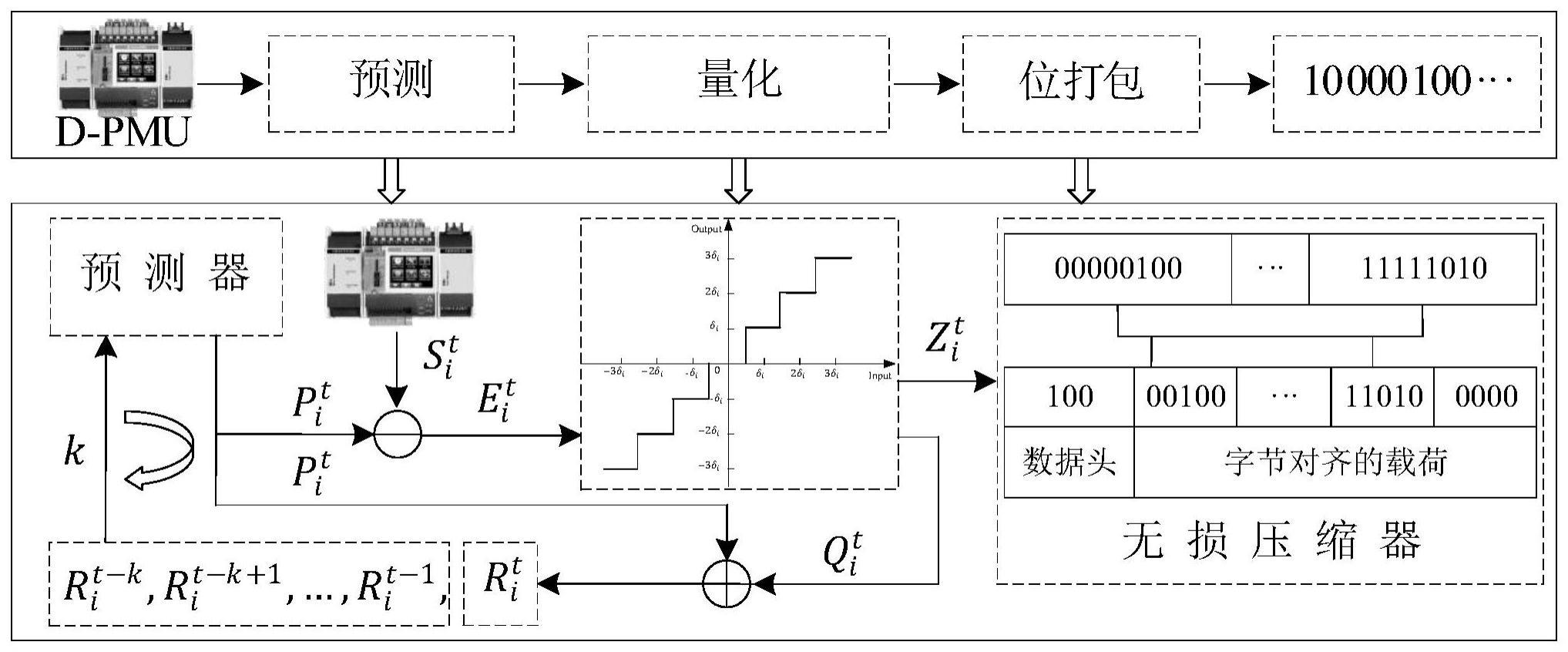
7.本发明所采用的技术方案是:一种面向配电网边缘计算装置的
d-pmu
数据实时压缩方法,包括如下步骤:
8.1)
输入压缩算法控制参数进行算法初始化,所述控制参数包括:归一化最小均方
预测器的阶数
k、
学习率
m、
归一化常数
α
、
权重参数矩阵w的初始值
、
量化步长矩阵
δ
、d-pmu
上送时间间隔
δ
t、
量化器占用的比特数b;
9.2)
实时读入一帧原始
d-pmu
数据,包括三相节点电压相量
、
三相支路电流相量
、
系统频率;采用归一化最小均方预测器对当前
d-pmu
数据帧进行预测,计算原始
d-pmu
数据帧与预测
d-pmu
数据帧间的误差,作为原始
d-pmu
数据帧与预测
d-pmu
数据帧间的预测误差;
10.3)
根据步骤
1)
中的量化步长矩阵,对步骤
2)
得到的原始数据帧与预测数据帧间的预测误差进行量化,得到量化后的
d-pmu
数据帧;
11.4)
对步骤
3)
得到的量化后的
d-pmu
数据帧进行位打包无损压缩;
12.5)
对归一化最小均方预测器的权重参数进行更新;
13.6)
跳转到步骤
2)
,执行下一帧的压缩
。
14.本发明的面向配电网边缘计算装置的
d-pmu
数据实时压缩方法,包括预测
、
量化
、
位打包无损压缩3个主要步骤,实现了接入配电网边缘计算装置的
d-pmu
数据的实时压缩,计算效率高
、
计算延时小,在保证较高数据精度的同时,高效降低了传输数据量大小,可以有效缓解海量高上送速率的
d-pmu
数据传输给配电网通信系统带来的负担
。
附图说明
15.图1是本发明面向配电网边缘计算装置的
d-pmu
数据实时压缩方法的整体流程图;
16.图2是位打包算法示例图
。
具体实施方式
17.下面结合实施例和附图对本发明的面向配电网边缘计算装置的
d-pmu
数据实时压缩方法做出详细说明
。
18.如图1所示,本发明的面向配电网边缘计算装置的
d-pmu
数据实时压缩方法,包括如下步骤:
19.1)
输入压缩算法控制参数进行算法初始化,所述控制参数包括:归一化最小均方预测器的阶数
k、
学习率
m、
归一化常数
α
、
权重参数矩阵w的初始值
、
量化步长矩阵
δ
、d-pmu(
配电网同步相量测量单元
)
上送时间间隔
δ
t、
量化器占用的比特数b;
20.2)
实时读入一帧原始
d-pmu
数据,包括三相节点电压相量
、
三相支路电流相量
、
系统频率;采用归一化最小均方预测器对当前
d-pmu
数据帧进行预测,计算原始
d-pmu
数据帧与预测
d-pmu
数据帧间的误差,作为原始
d-pmu
数据帧与预测
d-pmu
数据帧间的预测误差;所述的归一化最小均方预测器的预测步骤如下:
21.(2.1)
对于第1个原始
d-pmu
数据帧,预测数据帧为0;从第2个原始
d-pmu
数据帧至第k个原始
d-pmu
数据帧,每个预测数据帧均为当前时刻上一个时标对应的原始数据帧;
22.(2.2)
从第
k+1
个原始
d-pmu
数据帧开始,每个预测数据帧均为当前时刻前k个重构
d-pmu
数据帧的线性组合,计算公式如下:
[0023][0024]
式中,
i、j、q
为非负整数变量且j和q取值相等,代表第i种
d-pmu
数据在
t
时刻的预测值,代表第i种
d-pmu
数据在
t+j-k
时刻的重构值,代表对应第i种
d-pmu
数
据在
t
时刻第q个权重的值;
[0025]
(2.3)
原始
d-pmu
数据帧与预测
d-pmu
数据帧的预测误差通过下式计算:
[0026][0027]
式中,为第i种
d-pmu
数据在
t
时刻的预测误差,为第i种
d-pmu
数据在
t
时刻的原始数据值
。
[0028]
3)
根据步骤
1)
中的量化步长矩阵,对步骤
2)
得到的原始数据帧与预测数据帧间的预测误差进行量化,得到量化后的
d-pmu
数据帧;所述的量化过程如下:
[0029]
(3.1)
为了保证
d-pmu
数据实时压缩方法是误差有界的,所述的量化步长矩阵满足下式:
[0030]
δi=2ξiꢀꢀꢀꢀꢀ
(3)
[0031]
式中,
δi为量化步长矩阵
δ
中第i种
d-pmu
数据对应的量化步长值,
ξi为第i种
d-pmu
数据允许的最大绝对误差;
[0032]
(3.2)
量化过程的计算公式如下:
[0033][0034]
式中,是第i种
d-pmu
数据在
t
时刻预测误差的量化值且为带符号整数,
round(*)
代表对数据
*
进行四舍五入取整;
[0035]
(3.3)
量化器能够表示的范围为
[-2
b-1
+1,2
b-1-1]
,当不属于这个范围时,被设置为-2
b-1
,且以浮点数形式被保留在压缩数据中
。
[0036]
4)
对步骤
3)
得到的量化后的
d-pmu
数据帧进行位打包无损压缩;所述的位打包无损压缩过程如下:
[0037]
(4.1)
根据量化
d-pmu
数据帧中每一个量化数据值的符号,计算符号位
[0038][0039]
式中,是第i种
d-pmu
数据在
t
时刻预测误差的量化值且为带符号整数,是第i种
d-pmu
数据在
t
时刻的符号位;
[0040]
(4.2)
设为采用二进制表示时从低位至高位的第g个比特,g从0开始编码,从低位至高位遍历除符号位的每一个比特,迭代计算下式,得到的有效位数
[0041][0042]
式中,是第i种
d-pmu
数据在
t
时刻的有效位数,符号代表异或运算;
[0043]
(4.3)
计算量化后的
d-pmu
数据帧中所有数据对应的有效位数并将中的最大值作为该
d-pmu
数据帧的有效位数bs
;
[0044]
(4.4)
向压缩数据流中写入bs
;
[0045]
(4.5)
向压缩数据流中依次写入量化后的
d-pmu
数据帧中每一种数据对应的符号位和低bs
位;
[0046]
(4.6)
若量化后的
d-pmu
数据对应的压缩数据大小不是整数个字节,即第
(4.4)
步
和
(4.5)
步向压缩数据流中写入的比特位数不是整数个字节,在压缩数据流末尾补0进行字节对齐
。
[0047]
以图2为例,上方数据块为位打包前的一帧量化后的
d-pmu
数据,每个数据占据1个字节,在每个数据块中,虚线右侧为该数据的有效位,左侧为无意义的前导0或1,所以最大有效位数为
4。
下方数据块为位打包后的数据块,由于最大有效位数为4,所以数据头为
100
,压缩数据载荷为该数据的符号位和低4位
。
数据头和载荷共
68
个比特,所以末尾补
0000
进行字节对齐
。
[0048]
5)
对归一化最小均方预测器的权重参数进行更新;所述的权重参数更新过程如下:
[0049]
(5.1)
考虑到步骤
4)
是无损压缩,故时刻
t
的重构数据帧由下式计算得到:
[0050][0051][0052]
式中,为第i种
d-pmu
数据在
t
时刻的预测误差的重构值,为第i种
d-pmu
数据在
t
时刻的原始数据的重构值,是第i种
d-pmu
数据在
t
时刻预测误差的量化值且为带符号整数,
δi为量化步长矩阵
δ
中第i种
d-pmu
数据对应的量化步长值,代表第i种
d-pmu
数据在
t
时刻的预测值;
[0053]
(5.2)
采用随机梯度下降方法进行权重参数更新,其中,损失函数计算公式为:
[0054][0055]
式中,为第i种
d-pmu
数据在时刻
t
的损失函数;
[0056]
(5.3)
权重参数矩阵的更新公式为:
[0057][0058][0059][0060]
式中,
i、j、q
为非负整数变量,且j和q取值相等,代表对应第i种
d-pmu
数据在
t+1
时刻第q个权重的值,n为归一化的学习率,代表第i种
d-pmu
数据在
t+j-k
时刻的重构值
。
[0061]
6)
跳转到步骤
2)
,执行下一帧的压缩
。
[0062]
本发明的面向配电网边缘计算装置的
d-pmu
数据实时压缩方法对应的数据重构方法包括以下步骤:
[0063]
执行位打包无损压缩阶段的反变换
。
根据量化器占用的比特数b,从数据流中读取
log2b
个比特作为该帧数据的最大有效位数bs
。
根据最大有效位数bs
,依次读取每个数据类型对应的符号位及低bs
位,即可得到量化数据帧;
[0064]
根据量化数据帧和公式
(7)、
公式
(8)
,即可得到每个数据类型对应的重构数据帧,其中重构时需要的预测数据帧与压缩时的预测数据帧的计算方法完全相同,预测器的参数
更新方法也是完全相同
。
[0065]
下面给出具体实例:
[0066]
首先,介绍一下本发明实例采用的性能评价指标
。
本发明实例采用压缩比和数据重构精度两个指标衡量
d-pmu
数据实时压缩算法的性能
。
其中,压缩比取初始时刻
t0至结束时刻
t1时间段内原始
d-pmu
数据帧总大小
sr与压缩
d-pmu
数据帧总大小
sc的比值
。
[0067][0068]
数据重构精度采用最大绝对误差
(maximum absolute error,max)、
平均绝对误差
(mean absolute error,mae)
和平均相对误差百分比
(mean relative error percentage,mrep)3
个指标
。
理论上,最大绝对误差不大于量化步长的一半
。
平均绝对误差用来衡量相角数据或频率数据整体上的压缩精度,平均相对误差百分比用来衡量电压有效值或电流有效值数据整体上的压缩精度
。
计算公式如下:
[0069][0070][0071][0072]
式中,
δ
t
为
d-pmu
的上送间隔
。
[0073]
为了衡量本发明的面向配电网边缘计算装置的
d-pmu
数据实时压缩方法的性能,利用现场数据进行了测试,包括稳态运行场景和故障运行场景两种
。
现场
pmu
数据的电压等级为
10kv
,上送速率为
50
帧每秒
。
压缩算法涉及的数据类型包括三相的节点电压相量
、
三相的支路电流相量
、
系统频率数据共
13
种
。
原始数据类型为浮点型,占用4个字节
。
示例程序基于
c++
语言开发,为了模拟
pmu
数据的实时上送,
pmu
数据被一帧一帧地送入压缩器
。
[0074]
本发明的面向配电网边缘计算装置的
d-pmu
数据实时压缩方法的控制参数包括预测器的阶数
k、
权重参数矩阵w的初始值
、
学习率m以及量化步长矩阵
δ
。
这些参数决定了实时压缩算法的性能,具体的设置取决于场景需求
。
特别地,由于预测器基于历史数据进行预测,在算法执行时的前k个时刻,并不满足预测要求,取前一个时间间隔的数据作为当前时刻的预测值,对于首个时刻,预测值设置为
0。
[0075]
(1)
稳态运行下
d-pmu
数据实时压缩
[0076]
本发明实例选取了单个
d-pmu
稳态运行
800s
共
40000
帧数据进行测试
。
为了提高配电网稳态运行时预测器的精度,设置预测器的阶数k=8,即采用当前时刻前
160ms
的数据对当前时刻数据进行预测
。
权重参数矩阵w的任一元素的初始值设置为
1/k
,即预测器首次执行时的预测值为前k个数据的加权平均
。
学习率采用经验数值m=
0.5
,量化器占用的比特数为
8。
[0077]
量化步长矩阵
δ
的大小取决于对数据精度的需求,如表1所示
。
其中,电压有效值
、
电流有效值数据的精度分别设置为各自基准值的
0.02
%和
0.1
%,电流有效值数据波动相对较大,故精度设置较电压有效值低;考虑到配电网线路短,线路两端的相角差较小,量化步长大小设置为
0.02
°
。
系统频率数据本身波动小,量化步长设置为
0.0002hz。
其中
u0=
5.774kv
,
i0=
1000a。
[0078]
表1量化步长设置
[0079][0080]
(1.1)
数据重构精度
[0081]
表2定量地给出了稳态运行时压缩算法的精度
。
可以看出,原始数据与重构数据间的最大绝对误差是设定的量化步长的一半,平均绝对误差大致为量化步长的
1/4。
前者是由量化过程决定的,后者是因为预测误差是随机的,故每一个量化值前后半个步长内,预测误差呈现均匀分布的特点
。
平均相对误差方面,电压有效值达到
0.005
%左右的高精度,电流有效值达到了
0.03
%左右的高精度
。
这表明了本发明提出的压缩算法在压缩比为7左右时,仍保持较高的数据重构精度
。
[0082]
表2稳态运行时
d-pmu
数据重构精度
[0083][0084]
(1.2)
压缩比
[0085]
稳态运行时的压缩比为7左右,意味着至少
85.71
%左右的存储空间可以被节约
。
数据量的降低包括两个方面
。
一方面,采用8比特的量化器可以将原始数据帧中用4个字节表示的浮点型
d-pmu
数据降低4倍;另一方面,采用无损压缩算法进一步降低了量化数据中的冗余,实现了
1.8
左右的压缩比
。
[0086]
(1.3)
计算效率
[0087]
时延是衡量实时压缩算法的重要指标
。
本发明提出的面向配电网边缘计算装置的
d-pmu
数据实时压缩方法,运行时不需要时间窗,故时延主要指计算时延,由预测阶段
、
量化阶段和位打包阶段的运算产生,其中预测阶段占主要部分,涉及权重更新和数据预测两部
分
。
为了保证
d-pmu
数据压缩算法的实时性,计算时延应小于相邻两帧数据的时间间隔,即计算时延应小于
20ms
才能保证压缩算法的实时性
。
[0088]
为了衡量压缩算法在配电网边缘计算装置的适用性,选取树莓派
4b
作为边缘计算装置
。
其中,
cpu
为
arm cortex-a72@1.5ghz
,内存大小为
4gb。
在树莓派上进行
20
次仿真,统计
40000
帧数据总的压缩耗时,平均值为
1.706s
,每帧数据压缩的平均耗时为
0.043ms
,远小于该
d-pmu
数据的上送间隔
20ms
,故本发明提出的面向配电网边缘计算装置的
d-pmu
数据实时压缩方法在降低压缩数据大小的同时,保证了
d-pmu
数据的实时性,不影响配电网动态运行特性分析
。
[0089]
(2)
故障状态下
d-pmu
数据实时压缩
[0090]
由于
d-pmu
的高上送速率,
d-pmu
可以监测到配电网的动态运行特性
。
为了衡量本发明提出的面向配电网边缘计算装置的
d-pmu
数据实时压缩方法在配电网故障运行场景的适应性,本发明实例选取了实际配电网中相间短路试验获取的单个
d-pmu
的数据进行性能测试
。
在进行短路试验前,大部分负荷被切除,稳态时电流有效值大小仅为
10a
左右,随后a相和b相发生短暂的相间短路,持续时间为
0.3s
左右
。
本发明实例选取了短路发生前后共
300
帧数据进行测试
。
[0091]
短路发生瞬间,数据变化波动较大,为了增加预测器的动态响应,预测器的阶数k设置为4;电流有效值波动最大,由稳态时的
10a
陡增至
1800a
左右,将电流有效值数据的量化步长由
0.05
%
i0提高至1%
i0,
i0=
10a。
其他控制参数的取值与稳态时保持一致
。
[0092]
(2.1)
数据重构精度
[0093]
表3定量地给出了故障场景下压缩算法的精度
。
其中,每种类型数据的最大绝对误差不超过量化步长的一半;电流幅值数据平均相对误差百分比大约为
0.5
%,超过稳态运行时的数值,其他类型数据基本与稳态时保持一致,证明本方法在相间短路运行时能够保证较高的数据重构精度
。
[0094]
表3相间短路时
d-pmu
数据重构精度
[0095]
[0096][0097]
(2.2)
压缩比
[0098]
故障状态下,压缩比为
6.304
左右,相比稳态运行时较低
。
这是因为相间短路时数据变化剧烈,预测误差增大,导致量化数据数值较大,进而造成无损压缩时数据有效位数增加,压缩数据量增大
。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1