一种基于强化学习的视触融合精细操作方法与流程
本发明涉及航天器轨道控制方法,特别涉及一种基于强化学习的视触融合精细操作方法。
背景技术:
传统的在轨精细操作是基于手眼相机的视觉信号和压力传感器的压力信号实现对操作部位的插拔和切割等精细操作,视觉信号和触觉信息的分离导致信息的不完备,同时末端操作器的精细操控难以应对操作部位尺寸、形状等场景变化的空间操作任务,执行效率低、鲁棒性差、精度不足。
因此,针对失效目标的在轨操作任务,提供一种基于强化学习的视触融合精细操作方法实为必要,用以解决视触融合和基于强化学习的精细操作问题。
技术实现要素:
本发明的目的在于提供一种基于强化学习的视触融合精细操作方法,将视觉信号和触觉信号等不同模态的信号进行表征,实现视触信息融合,并基于视触融合信息开展基于强化学习精细操作技术研究,建立状态-动作对的映射关系,寻找得到操控目标的最优动作序列,提高在轨操控的控制精度和柔顺性,使操控平台具备一定的自主操作能力,实现对目标的精细操作。
一种基于强化学习的视触融合精细操作方法,该方法包含以下步骤:
s1、通过卷积神经网络对视觉信号进行处理,得到视觉表征的特征向量;s2、通过对触觉序列的分段、特征提取和聚类处理,得到触觉表征的特征向量;
s3、基于视觉表征的特征向量和触觉表征的特征向量,并利用联合核稀疏编码,获得视触融合信息;
s4、基于所述视触融合信息,采用ddpg算法,训练策略网络生成下一步的运动轨迹,训练价值网络来评价当前运动轨迹的优劣;通过与空间机器人操作系统环境的接触交互,获取指定任务的控制策略,实现动作序列的优化。
优选地,所述步骤s2中,进一步包含:
所述卷积神经网络是以原始图像数据作为输入,采用alexnet网络模型中的结构参数,所述卷积神经网络包含卷积层、池化层和全连接层;
所述卷积层通过卷积核对输入层进行特征提取,所述卷积核对卷积神经网络的输入层进行扫描,对于每一个位置,输入层与卷积核的对应元素进行点积运算,得到该区域的局部特征,其中,卷积核对输入层每完成一遍扫描,完成一次卷积操作,得到一张特征图谱,多个卷积核分别将每次卷积操作得到的特征图谱依次排列,输出一个三维的卷积特征图谱,最终得到视觉图像的特征表示。
优选地,所述步骤s2中,进一步包含:
所述触觉序列的分段是指在得到触觉序列化的动态数据的基础上,对其进行整体建模,在时间维度将触觉序列进行切分建模,将触觉序列划分为一系列子触觉序列。
优选地,所述触觉序列的特征提取进一步包含:
基于线性动态系统的方法对每组子触觉序列进行特征提取,线性动态系统的表达式如下:
x(t+1)=ax(t)+bv(t)
y(t)=cx(t)+w(t)
其中,x(t)∈rp为t时刻的隐状态序列;y(t)为t时刻的系统实际输出值;a∈rn×n为隐状态动态矩阵,c∈rp×n为系统的隐状态输出矩阵,w(t)~n(0,r),bv(t)~n(0,q)分别表示估计值和状态噪声;观测矩阵元组(a,c)分别刻画系统的动态性和空间形态,将其作为输入触觉序列的特征描述子,在求得特征描述子后使用马丁距离作为度量计算动态特征(a,c)之间的距离。
优选地,所述触觉序列的聚类处理进一步包含:
在求得特征描述子后使用马丁距离作为度量计算动态特征(a,c)之间的距离后,使用k-medoid算法进行聚类,计算出特征描述子与各自聚类中心之间的最小距离,在此基础上进行分组,将多个聚类中心和分组构建为码书,每组特征描述子(a,c)被称为码词;
使用码书对触觉序列表征得到系统包模型,由特征词频率算法统计码词在码书中的分布特点,并形成特征向量;
当在第i组触觉序列,第j组码词出现的次数为cij次,则有:
其中,m为触觉序列个数;k为聚类中心点个数;hij表示在第i组触觉序列,第j组码词出现的频率,即提取的一组触觉特征向量。
优选地,所述步骤s3中进一步包含:
深度稀疏编码方法挖掘不同模态的潜在子空间描述形式,并建立联合核稀疏编码来对多模态信息进行联合建模,融合不同模态信息的相容部分,并剔除不相容部分;
核稀疏编码通过建立一个高维特征空间,取代原来的空间,以便从字典中捕捉信号的非线性结构,具体如下:
当编码之前有m个模态信息,nm是训练样本的个数,mm代表第m个模态数据特征描述,m=1,2,…m;
用映射函数将训练样本映射到一个更高维空间,将φm(·):mm→hm作为从mm映射到高维积空间hm的隐式非线性映射,则φm(om)称为高维空间的字典,且将联合核稀疏编码放松为组联合核稀疏编码,要求对应同一个组内的元素被同时激活。
优选地,所述步骤s4中的ddpg算法包含策略网络和价值网络,所述策略网络包括策略估计网络和策略现实网络,所述策略估计网络用于输出实时的动作,供所述策略现实网络使用,所述策略现实网络用于更新价值网络;
所述价值网络包括价值估计网络和价值现实网络,均是用于输出当前状态的价值,所述价值估计网络的输入是当前策略施加动作;
所述策略估计网络和所述价值估计网络用于产生训练数据集,所述策略现实网络和所述价值现实网络用于训练优化网络参数。
与现有技术相比,本发明的有益效果在于:本发明利用触觉和视觉的多模态信息之间的冗余性和互补性,使得机器人能够获得更加全面的外界信息,并基于强化学习进行柔性灵巧手的精细操作训练,提高机器人的信息感知和精细操作精度以及任务决策的正确率等,为失效目标的在轨模块更换、帆板辅助展开等操作任务提供了技术支撑。
附图说明
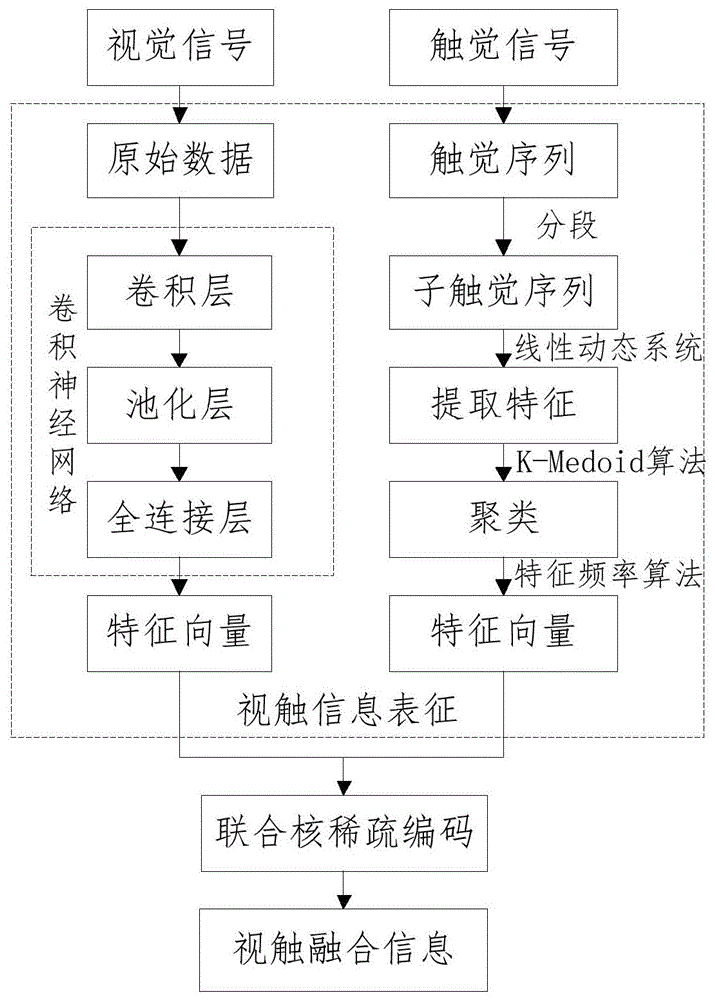
图1为本发明的视触融合状态感知流程图;
图2为本发明的基于强化学习的精细操作任务流程图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图1-图2结合所示,本发明提供了一种基于强化学习的视触融合精细操作方法,主要包括视触融合和基于强化学习的视触融合精细操作,包括如下步骤:
s1、通过卷积神经网络对视觉信号进行处理,得到视觉表征的特征向量。
所述步骤s1中,所述卷积神经网络包含卷积层、池化层和全连接层。示例地,所述卷积神经网络的结构采用alexnet网络模型中的结构参数,包含五层卷积层、三层池化层和两层全连接层。
具体地,卷积层通过卷积核对输入层进行特征提取,卷积核对神经网络输入层进行扫描,对于每一个位置,输入层与卷积核的对应元素进行点积运算,得到该区域的局部特征。卷积核对输入层每完成一遍扫描,即完成一次卷积操作,得到一张特征图谱;对于多个卷积核,将每次卷积操作得到的特征图谱依次排列,输出一个三维的卷积特征图谱。分别在第1、2和5层卷积层后加入步长为2的最大值池化层,通过对输入信号进行抽象,以求在不损失有用信号的前提下逐渐减小信号规模,降低参数数量,加快运算速度,并避免过拟合现象的产生;最后,在第五层卷积层后连接两层全连接层及输出层,全连接层与普通神经网络一样,其中的每一个神经元都与输入层的每一个神经元相连。由以上可以看出,卷积神经网络以原始图像和雷达数据作为输入,利用卷积核得到每个输入层的局部特征,再对原始信息的特征逐层进行抽象,最终可自动学习得到视觉图像的特征表示。
s2、通过对触觉序列的分段、特征提取和聚类处理,得到触觉表征的特征向量。
所述步骤s2中,触觉信息通过多阵列电子皮肤采集,可得到各种不同材质、形状目标物的触觉数据,是序列化的动态数据,需要对其进行整体建模而不仅针对单触觉帧。同时,由于物体的表面材质、物体形状、抓取姿态等不同,触觉序列在空间维度上各具特点。本发明在时间维度拟将触觉序列进行切分建模,将触觉序列划分为一系列子触觉序列,基于线性动态系统的方法对每组子触觉序列进行特征提取。线性动态系统的表达式如下:
x(t+1)=ax(t)+bv(t)
y(t)=cx(t)+w(t)
其中,x(t)∈rp为t时刻的隐状态序列;y(t)为t时刻的系统实际输出值;a∈rn×n为隐状态动态矩阵;c∈rp×n为系统的隐状态输出矩阵;w(t)~n(0,r),bv(t)~n(0,q)分别表示估计值和状态噪声;观测矩阵元组(a,c)分别刻画了系统的动态性和空间形态,因而将其作为输入触觉序列的特征描述子。在求得特征描述子之后使用马丁距离作为度量计算动态特征(a,c)之间的距离,并使用k-medoid算法进行聚类,计算出特征描述子与各自聚类中心之间的最小距离,在此基础上进行分组,将多个聚类中心和其分组构建为码书,每组特征描述子(a,c)被称为码词。最后使用码书对触觉序列表征得到系统包模型,由特征词频率(tf,termfrequency)算法统计码词在码书中的分布特点,并形成特征向量。
假设在第i组触觉序列,第j组码词出现的次数为cij次,则有:
其中,m为触觉序列个数;k为聚类中心点个数;hij表示在第i组触觉序列;第j组码词出现的频率,即提取的一组触觉特征向量。
由上可知,基于线性动态系统的建模方法可以有效提取触觉时空序列的特征,并通过k-medoid算法衡量特征之间的马丁距离实现对特征的聚类,结合特征词频率算法计算触觉特征向量。
s3、通过联合核稀疏编码,获得视触融合信息,如图1所示。
所述步骤s3中,进一步包含:采用深度稀疏编码方法挖掘不同模态的潜在子空间描述形式,并建立联合核稀疏编码来对多模态信息进行联合建模,有效地融合不同模态信息的相容部分,并剔除不相容部分。核稀疏编码通过建立一个高维特征空间,取代原来的空间,以便更有效地从字典中捕捉信号的非线性结构。
假设编码之前有m个模态信息,nm是训练样本的个数,mm代表第m个模态数据特征描述,m=1,2,…m。需用正确的映射函数将训练样本映射到一个更高维空间,因此将φm(·):mm→hm作为从mm映射到高维积空间hm的隐式非线性映射,则φm(om)称为高维空间的字典,且空间机器人操作系统可以将联合核稀疏编码放松为组联合核稀疏编码,只要求对应同一个组内的元素被同时激活即可。
s4、基于空间机器人视触融合信息,采用ddpg(deepdeterministicpolicygradient)算法,训练策略网络生成下一步的运动轨迹,并训练值函数网络来评价当前轨迹的优劣。通过与环境的接触交互,获取指定任务的控制策略,实现动作序列的优化,如图2所示。
所述步骤s4中,进一步包含:
ddpg算法包含策略网络和价值网络:策略网络包括策略估计网络和策略现实网络,其中策略估计网络用来输出实时的动作,供策略现实网络使用,而策略现实网络用来更新价值网络系统。价值网络包括价值估计网络和价值现实网络,都在输出当前状态的价值,但价值估计网络的输入是当前策略施加动作。其中策略估计网络和价值估计网络主要用于产生训练数据集,而策略现实网络和价值现实网络主要训练优化网络参数。
ddpg算法流程如下:
1)分别初始化策略估计网络参数θμ和价值估计网络参数θq;
2)分别将策略估计网络参数θμ和价值估计网络参数θq拷贝给对应的策略现实网络参数θμ′和价值现实网络参数θq′:
θμ′←θμ,θq′←θq
3)初始化经验回放数据库r;
4)对于每一个训练回合,执行下列任务:
(1)初始化奥恩斯坦-乌伦贝克(ornstein-uhlenbeck,ou)随机过程,该ou过程表示为一个存在随机噪声的均值回归。
(2)对于每一个时间步长,执行下列任务:
①策略网络根据当前的视触融合状态st,基于估计策略μ和ou随机过程生成的噪声,选择一个动作at,at=μ(st|θμ)+νt,通过空间机器人操作系统来执行at,返回奖励γt和新的视触融合状态st+1;
②重复过程①得到多组数据(st,at,γt,st+1),并把它们存入r中,作为训练网络的数据集;
③在r中随机选择n组数据,作为策略估计网络、价值估计网络的最小批的训练数据,用(si,ai,γi,si+1)(i=1,2…n)表示最小批中的单组数据;
④采用均方误差确定价值网络的损失函数
⑤采用adam(一种梯度下降法)优化器更新价值估计网络θq;
⑥计算策略网络的策略梯度,表示为
⑦采用adam优化器更新策略估计网络θμ;
⑧更新策略现实网络θμ′和价值现实网络θq′:
式中τ=0.001。
⑨当时间步长小于最大步长t时,转到①,否则退出循环,该训练回合结束。
(3)当训练回合数小于最大训练回合数n时,转到(1),否则退出循环,训练过程结束。
基于上述ddpg方法,在输入的视触融合信息中实时的学习适合操作目标物的动作序列,实现模块更换和帆板辅助展开等精细操作任务。
综上所述,本发明的基于强化学习的视触融合精细操作方法是基于末端操作工具的手眼相机和触觉传感器分别获得视觉信息和触觉信息,通过联合核稀疏编码获得视触融合信息,并基于视触融合信息和强化学习方法,实现末端精细操作。
尽管本发明的内容已经通过上述优选实施例作了详细介绍,但应当认识到上述的描述不应被认为是对本发明的限制。在本领域技术人员阅读了上述内容后,对于本发明的多种修改和替代都将是显而易见的。因此,本发明的保护范围应由所附的权利要求来限定。
- 还没有人留言评论。精彩留言会获得点赞!